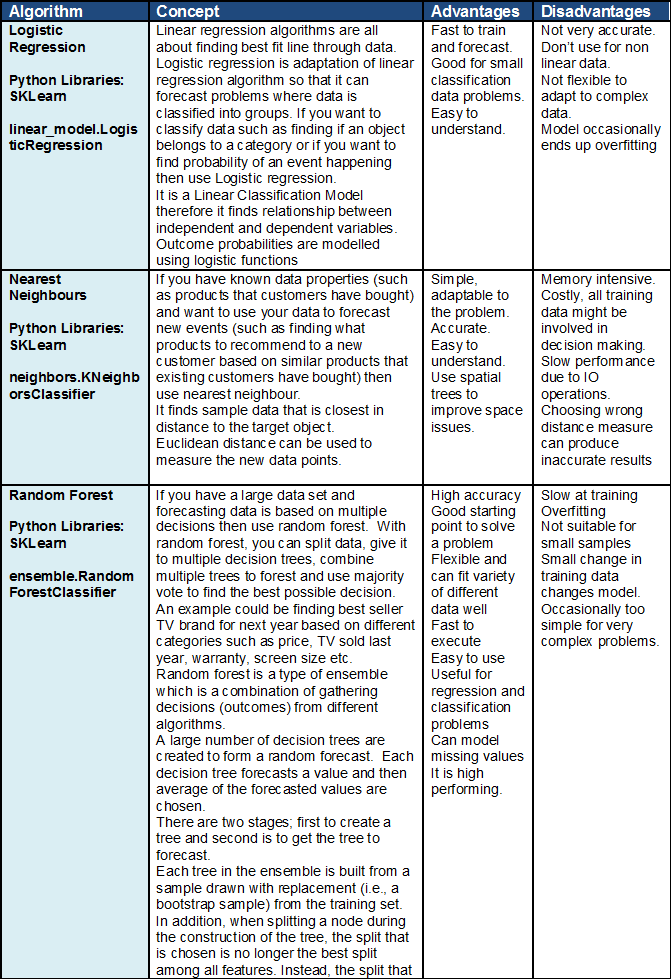
The scope of this research is primarily on the performance analysis of disease prediction approaches using different variants of supervised machine learning algorithms. Disease prediction and in a broader context, medical informatics, have recently gained significant attention from the data science research community in recent years. Models based on these algorithms use labelled training data of patients for training . For the test set, patients are classified into several groups such as low risk and high risk. To avoid the risk of selection bias, from the literature we extracted those articles that used more than one supervised machine learning algorithm. The same supervised learning algorithm can generate different results across various study settings.

There is a chance that a performance comparison between two supervised learning algorithms can generate imprecise results if they were employed in different studies separately. On the other side, the results of this study could suffer a variable selection bias from individual articles considered in this study. These articles used different variables or measures for disease prediction. We noticed that the authors of these articles did not consider all available variables from the corresponding research datasets. The inclusion of a new variable could improve the accuracy of an underperformed algorithm considered in the underlying study, and vice versa. Another limitation of this study is that we considered a broader level classification of supervised machine learning algorithms to make a comparison among them for disease prediction.

We did not consider any sub-classifications or variants of any of the algorithms considered in this study. For example, we did not make any performance comparison between least-square and sparse SVMs; instead of considering them under the SVM algorithm. A third limitation of this study is that we did not consider the hyperparameters that were chosen in different articles of this study in comparing multiple supervised machine learning algorithms. It has been argued that the same machine learning algorithm can generate different accuracy results for the same data set with the selection of different values for the underlying hyperparameters .

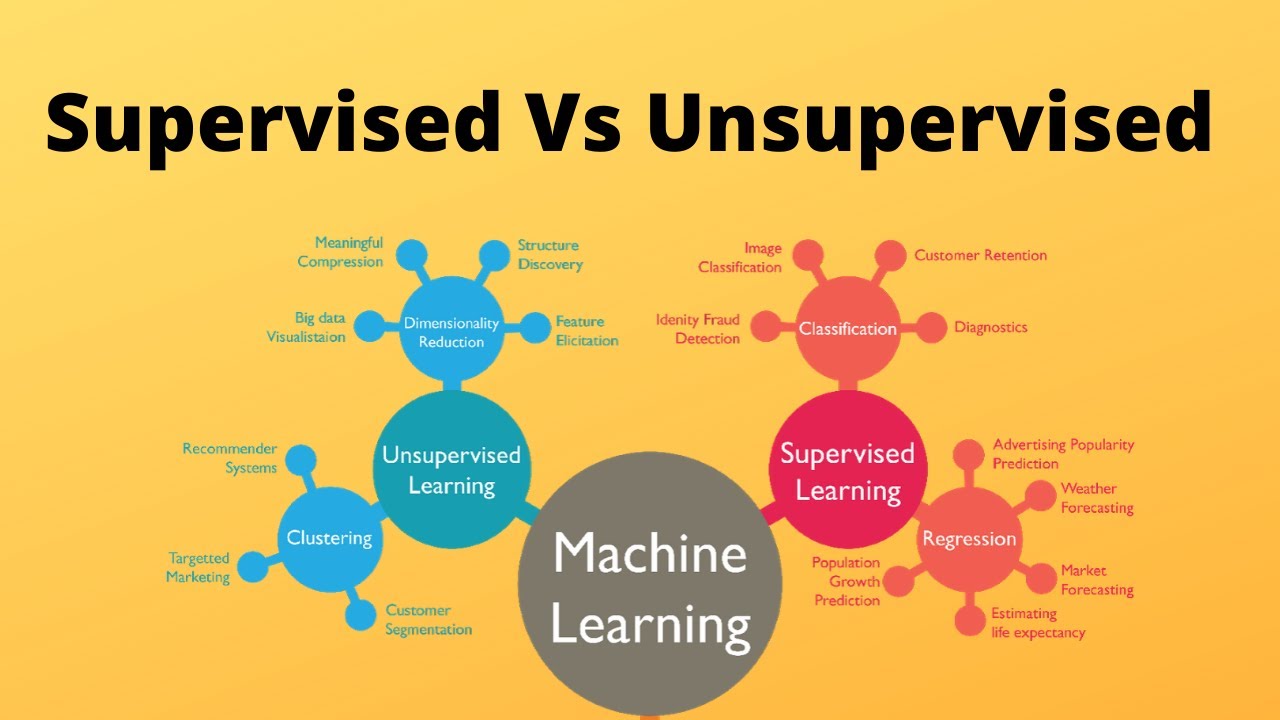
The selection of different kernels for support vector machines can result a variation in accuracy outcomes for the same data set. Similarly, a random forest could generate different results, while splitting a node, with the changes in the number of decision trees within the underlying forest. Unsupervised machine learning algorithms are not trained by data scientists. Instead, they use deep learning to identify patterns in data by combing through sets of unlabeled training data and observing correlations. Unsupervised learning models receive no information about what to look for in the data or which data features to examine.
Despite their accuracy and learning capacity, deep neural networks require large amount of data and computational load. In the previous two machine learning types, there is either labeled or unlabeled data to assist training. Data labeling is an expensive and time-consuming process that requires highly-trained human resources.

In that regard, there are cases where labels are unavailable in most observations but present in just a handful, and this is where semi-supervised machine learning comes in. Let's take an example of a photo archive that contains both labeled and unlabeled images. Semi-supervised machine learning attempts to solve problems that lie between supervised and unsupervised learning by discovering and learning the structure of the input variables. Given the growing applicability and effectiveness of supervised machine learning algorithms on predictive disease modelling, the breadth of research still seems progressing. Specifically, we found little research that makes a comprehensive review of published articles employing different supervised learning algorithms for disease prediction.

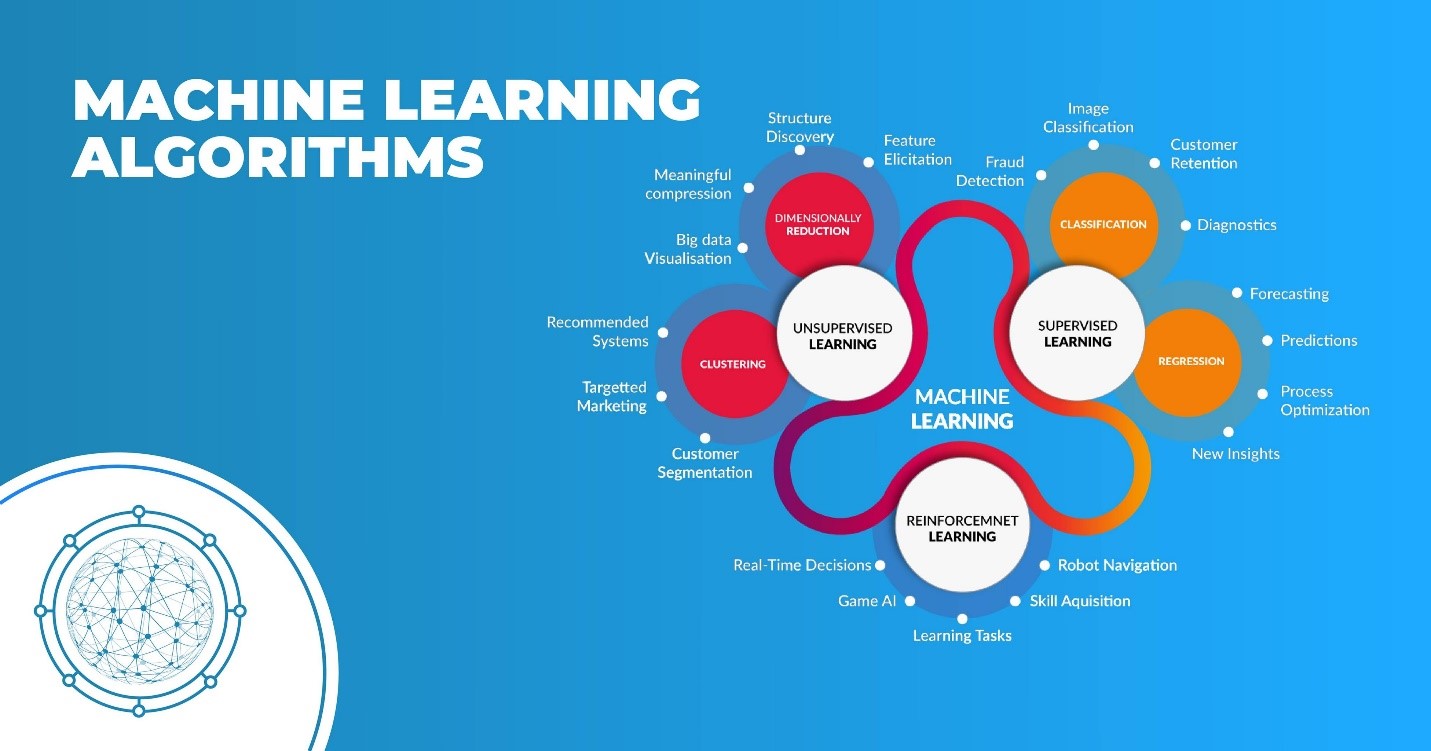
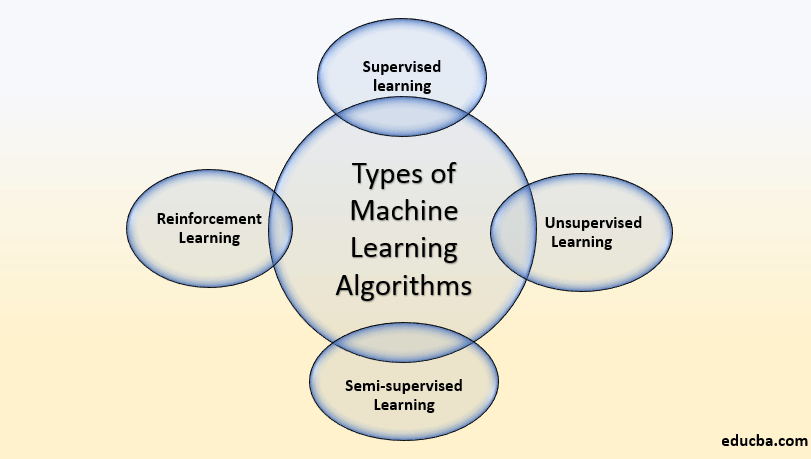
Therefore, this research aims to identify key trends among different types of supervised machine learning algorithms, their performance accuracies and the types of diseases being studied. In addition, the advantages and limitations of different supervised machine learning algorithms are summarised. Supervised learning is the most common type ofmachine learningalgorithms. It uses a known dataset to train an algorithm with a known set of input data and known responses to make predictions. The training dataset includes labeled input data that pair with desired outputs or response values. From it, the supervised learning algorithm seeks to create a model by discovering relationships between the features and output data and then makes predictions of the response values for a new dataset.
Section 1 gives an overview of machine learning in investment management. Section 2 defines machine learning and the types of problems that can be addressed by supervised and unsupervised learning. Section 3 describes evaluating machine learning algorithm performance.

Key supervised machine learning algorithms are covered in Sections 4–8, and Sections 9–12 describe key unsupervised machine learning algorithms. Neural networks, deep learning nets, and reinforcement learning are covered in Sections 13 and 14. Section 15 provides a decision flowchart for selecting the appropriate ML algorithm. Self-trained algorithms are all examples of semi-supervised learning.

Developers can add to these models a Naive Bayes classifier, which allows self-trained algorithms to perform classification tasks simply and easily. When developing a self-trained model, researchers train the algorithm to recognize object classes on a labeled training set. Once that cycle is finished, researchers upload the correct self-categorized labels to the training data and retrain.

Self-trained models are popular in natural language processing and among organizations with limited labeled data sets. Primarily leveraged for deep learning algorithms, neural networks process training data by mimicking the interconnectivity of the human brain through layers of nodes. If that output value exceeds a given threshold, it "fires" or activates the node, passing data to the next layer in the network. Neural networks learn this mapping function through supervised learning, adjusting based on the loss function through the process of gradient descent.

When the cost function is at or near zero, we can be confident in the model's accuracy to yield the correct answer. Supervised machine learning algorithms uncover insights, patterns, and relationships from a labeled training dataset – that is, a dataset that already contains a known value for the target variablefor each record. A labeled data means that some of the data is tagged with the correct output. Supervised learning is used for regression and classification to predict a procedure's output.
Algorithms in supervised learning learn from the labeled training data, which is beneficial for predicting unpredicted data outcomes. It takes time to build, scale and deploy accurate machine learning models successfully. Besides that, supervised learning also needs an expert team of skilled data scientists.

In this form of machine learning, we allow the algorithm to self-discover the underlying patterns, similarities, equations, and associations in the data without adding any bias from the users' end. Although the end result of these is totally unpredictable and cannot be controlled, Unsupervised Learning finds its place is advanced exploratory data analysis and especially, Cluster Analysis. Artificial neural networks are a set of machine learning algorithms which are inspired by the functioning of the neural networks of human brain. They were first proposed by McCulloch and Pitts and later popularised by the works of Rumelhart et al. in the 1980s .. In the biological brain, neurons are connected to each other through multiple axon junctions forming a graph like architecture.
Machine Learning Algorithms Types These interconnections can be rewired (e.g., through neuroplasticity) that helps to adapt, process and store information. Likewise, ANN algorithms can be represented as an interconnected group of nodes. The output of one node goes as input to another node for subsequent processing according to the interconnection. Nodes are normally grouped into a matrix called layer depending on the transformation they perform. Apart from the input and output layer, there can be one or more hidden layers in an ANN framework.

Nodes and edges have weights that enable to adjust signal strengths of communication which can be amplified or weakened through repeated training. Based on the training and subsequent adaption of the matrices, node and edge weights, ANNs can make a prediction for the test data. Figure7 shows an illustration of an ANN with its interconnected group of nodes. Machine learning algorithms employ a variety of statistical, probabilistic and optimisation methods to learn from past experience and detect useful patterns from large, unstructured and complex datasets . Most of these applications have been implemented using supervised variants of the machine learning algorithms rather than unsupervised ones. In the supervised variant, a prediction model is developed by learning a dataset where the label is known and accordingly the outcome of unlabelled examples can be predicted .

In deep learning, sophisticated algorithms address complex tasks (e.g., image classification, natural language processing). Deep learning is based on neural networks, highly flexible ML algorithms for solving a variety of supervised and unsupervised tasks characterized by large datasets, non-linearities, and interactions among features. In reinforcement learning, a computer learns from interacting with itself or data generated by the same algorithm. Unsupervised machine learning algorithms, on the other hand, learn what normal behavior is, and then apply a statistical technique to determine if a specific data point is an anomaly.

A system based on this kind of anomaly detection technique is able to detect any type of anomaly, including ones which have never been seen before. The main challenge in using unsupervised machine learning methods for detecting anomalies is determining what is considered normal for a given time series. This research attempted to study comparative performances of different supervised machine learning algorithms in disease prediction. Since clinical data and research scope varies widely between disease prediction studies, a comparison was only possible when a common benchmark on the dataset and scope is established.

Therefore, we only chose studies that implemented multiple machine learning methods on the same data and disease prediction for comparison. Regardless of the variations on frequency and performances, the results show the potential of these families of algorithms in the disease prediction. It found 55 articles that used more than one supervised machine learning algorithm for the prediction of different diseases. Out of the remaining 281 articles, only 155 used one of the seven supervised machine learning algorithms considered in this study. The rest 126 used either other machine learning algorithms (e.g., unsupervised or semi-supervised) or data mining methods other than machine learning ones. ANN was found most frequently (30.32%) in the 155 articles, followed by the Naïve Bayes (19.35%).
Model development is not a one-size-fits-all affair -- there are different types of machine learning algorithms for different business goals and data sets. For example, the relatively straightforward linear regression algorithm is easier to train and implement than other machine learning algorithms, but it may fail to add value to a model requiring complex predictions. As ML is a complex process especially for supervised learning, researchers should consider before speed of training, memory usage, predictive accuracy and interpretability of their models. Concerning the classification models, algorithms are divided in binary vs. multiclass classification. Decision tree is one of the earliest and prominent machine learning algorithms. A decision tree models the decision logics i.e., tests and corresponds outcomes for classifying data items into a tree-like structure.

The nodes of a DT tree normally have multiple levels where the first or top-most node is called the root node. All internal nodes (i.e., nodes having at least one child) represent tests on input variables or attributes. Depending on the test outcome, the classification algorithm branches towards the appropriate child node where the process of test and branching repeats until it reaches the leaf node . DTs have been found easy to interpret and quick to learn, and are a common component to many medical diagnostic protocols . When traversing the tree for the classification of a sample, the outcomes of all tests at each node along the path will provide sufficient information to conjecture about its class.

An illustration of an DT with its elements and rules is depicted in Fig.3. Supervised learning models can be a valuable solution for eliminating manual classification work and for making future predictions based on labeled data. However, formatting your machine learning algorithms requires human knowledge and expertise to avoid overfitting data models. If supervised learning uses labeled input and output data, an unsupervised learning algorithm works on its own to discover the structure of unlabeled data.

Unsupervised learning comes in handy when the human expert has no idea what to look for in the data. Unlike supervised learning, it is best suited for more complex tasks, including descriptive modeling and pattern detection. The final dataset contained 48 articles, each of which implemented more than one variant of supervised machine learning algorithms for a single disease prediction.

All implemented variants were already discussed in the methods section as well as the more frequently used performance measures. Based on these, we reviewed the finally selected 48 articles in terms of the methods used, performance measures as well as the disease they targeted. We noticed that four groups of authors reported their study results in two publication outlets (i.e., book chapter, conference and journal) using the same or different titles.

We further excluded another three articles since the reported prediction accuracies for all supervised machine learning algorithms used in those articles are the same. For each of the remaining 48 articles, the performance outcomes of the supervised machine learning algorithms that were used for disease prediction were gathered. Two diseases were predicted in one article and two algorithms were found showing the best accuracy outcomes for a disease in one article . In that article, five different algorithms were used for prediction analysis.

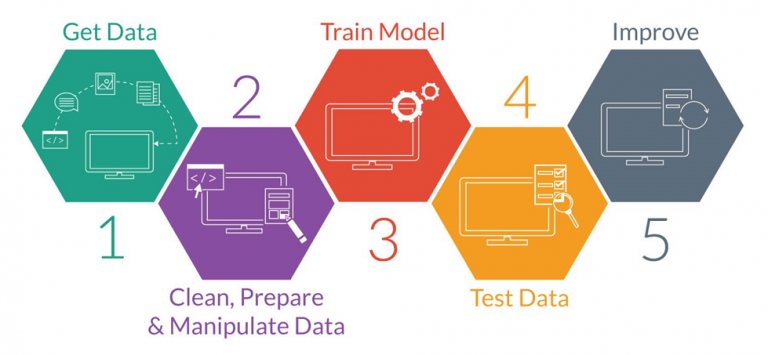
The overall data collection procedure along with the number of articles selected for different diseases has been shown in Fig.9. Supervised machine learning algorithms have been a dominant method in the data mining field. Disease prediction using health data has recently shown a potential application area for these methods. This study aims to identify the key trends among different types of supervised machine learning algorithms, and their performance and usage for disease risk prediction. The operator provides the machine learning algorithm with a known dataset that includes desired inputs and outputs, and the algorithm must find a method to determine how to arrive at those inputs and outputs. While the operator knows the correct answers to the problem, the algorithm identifies patterns in data, learns from observations and makes predictions.

The algorithm makes predictions and is corrected by the operator – and this process continues until the algorithm achieves a high level of accuracy/performance. We can utilize and harness powerful tools like Python and R to implement various types of machine learning algorithms to make the most out of the data. Apart from that, we can also integrate these models into various end-user applications. Semi-supervised learning falls somewhere between the supervised and unsupervised machine learning techniques by incorporating elements of both methods. This method is used when there is only a limited set of data available to train the system, and as a result, the system is only partially trained.
The information the machine generates during this partial training is called pseudo data and later on computer combines both labeled and the pseudo-data to make predictions. Traditionally, standard statistical methods and doctor's intuition, knowledge and experience had been used for prognosis and disease risk prediction. This practice often leads to unwanted biases, errors and high expenses, and negatively affects the quality of service provided to patients . With the increasing availability of electronic health data, more robust and advanced computational approaches such as machine learning have become more practical to apply and explore in disease prediction area. In the literature, most of the related studies utilised one or more machine learning algorithms for a particular disease prediction. For this reason, the performance comparison of different supervised machine learning algorithms for disease prediction is the primary focus of this study.
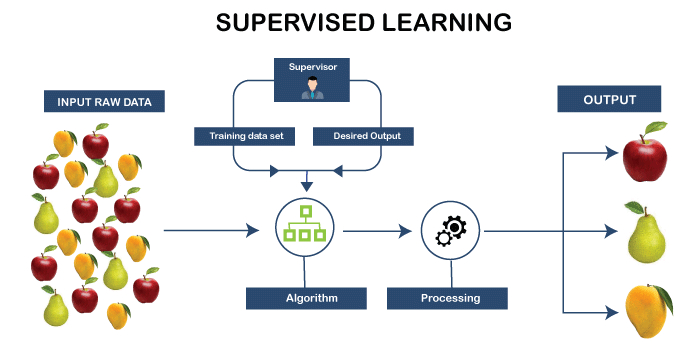
In this study, extensive research efforts were made to identify those studies that applied more than one supervised machine learning algorithm on single disease prediction. Two databases (i.e., Scopus and PubMed) were searched for different types of search items. Thus, we selected 48 articles in total for the comparison among variants supervised machine learning algorithms for disease prediction. Supervised learning is applied when past learnings are applied to the new data set to predict future events. In this type of learning, the algorithm is getting trained on a labeled dataset.

It has a set of input variables and an output variable that identifies the mapping function. When input data is fed into the algorithm, it balances its weights until the algorithm has been fitted correctly. This happens to cross-validate and to ensure that the algorithm avoids overfitting or underfitting.





No comments:
Post a Comment
Note: Only a member of this blog may post a comment.